

We have started an unusual way to introduce the rudimentary fundamentals of the discrete Kalman filter. Now we are going to explore some of the math behind. Note that we will concentrate on the statistical approach an we will only develop equations for the most simple scalar filter. Please refer to the Intuitive introduction to the scalar Kalman filter page, where we develop the Roger Rabbit experiments.
1. State equation
Literature:
- J, V. GRABINER, "Who Gave You the Epsilon? Cauchy and the Origines of Rigurous Calculus", The American Mathematical Monthly, March 1983, Vol. 90, 3, pp. 185-184
- R. RABENSTEIN's SYSTOOL (Description of the Shannon-Nyquist Sampling theorem and more.)
- Markov chain applet
- Wikipedia's excellent article about the normal distribution
- Wikipedia also describes well the colour of noise
- Funny introduction to recursion
Roger Rabbit's movement is approximated as
a linear motion with constant speed. The reality diverges from this simplified view.
Obviously there are small, but significant variations in speed as can be
seen on (Fig.1). However the graphical description of Roger's motion does not
correspond to reality either, because we know from Newton's laws that the velocity
of a mass cannot change so abruptly. The graph suggests discontinuities through the interpolation lines
between the sampled data-points that are drawn for each time step Dt.
Any realistic plot of Roger's speed would appear much smoother. However, such
a continuous description would presuppose infinitesimal time steps dt
and, according to Cauchy's
definition of a continuous function f,
for any t and dt, there would exist a number e
that ![]() .
This continuity postulate would lead to the conclusion that two infinitesimally adjacent points
are not independent of each other, because they
always are localized in close proximity defined by dt and e.
.
This continuity postulate would lead to the conclusion that two infinitesimally adjacent points
are not independent of each other, because they
always are localized in close proximity defined by dt and e.
In the digital-countable world we are accustomed to divide time into steps Dt. It is clear that the discretized function can no longer represent all the points between two adjacent points in time. There necessarily is a loss of information -although the sampling theorem teaches us that under certain conditions periodic functions can be entirely reproduced from the digitalization-. The time-discretization always requires a careful preliminary fixing of the time step in order to keep the losses of information as small as possible. By contrast, in many cases it is desired to keep the beat slow enough, so as to assure that any function-value depends at the utmost on its predecessor, or even more strictly that two adjacent points are statistically independent. Such a function or process then is called a Markov process. Both sampling requirements must be well balanced, when fixing the time step.
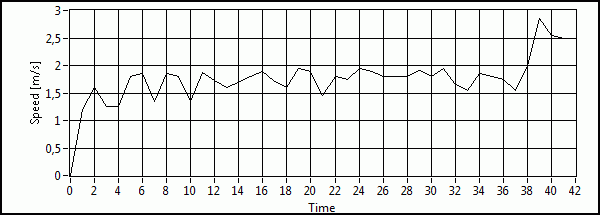
Fig. 1 : Roger Rabbit's speed suffers from noise. (mean m=1.76 m/s, variance Q=s2=0.55).
The discrete description of Roger Rabbit's path can be considered as a Markov process, because each new position only depends on the previous one. The new state therefore can be expressed in a stochastic difference equation that starts from the preceding step:
![]() ,
( 1 )
,
( 1 )
where x symbolizes the process-state, t the discrete point in time and w represents the noise that partly corrupts the presumed constant speed s. Dt is supposed to equal 1[sec]. The noise itself has zero mean and is normally distributed. If we generate a dozen of noise classes over the range [-2,2] and we count the number of times that a certain divergence w from the mean (m=1.76) belongs to one of the classes, we can draw a histogram. If the occurrences are divided by the total number of data, we obtain the relative frequency distribution that, due to the very small number of samples, only roughly follows the normal probability density distribution with variance Q=0.55 as it can be seen on (Fig. 2). (Take note that we suppose the noise to be white, which means that the wave-spectrum is equally distributed.) The recursive equation above suggests that we go back step by step down to negative infinity in time, which obviously doesn't make any sense. It is therefore assumed that the system starts at t=0 with an initial state value x(0)=0. The very first estimate also is set to zero.
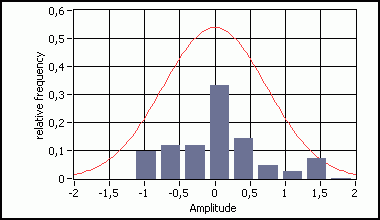
Fig. 2 : The relative frequency distribution of the noise with the Gaussian probability density.
It is clear that we are not able to determine the state of Roger's actual location directly. We cannot yield the actual noise component either.
2. Measurement equation
Literature:
- P. S. MAYBECK, Stochastic models, estimation, and control, Vol. 1., Academic Press, N.Y., 1979. download by permission
We have measured Roger's path while estimating the noise variance to R=4. A typical relative frequency distribution of the measurement errors under these conditions is shown on (Fig. 3) together with the corresponding probability density function. The measurements are related to the real state through the equation:
![]() ,
( 2 )
,
( 2 )
where z symbolizes the actual measurement and v the measurement noise.
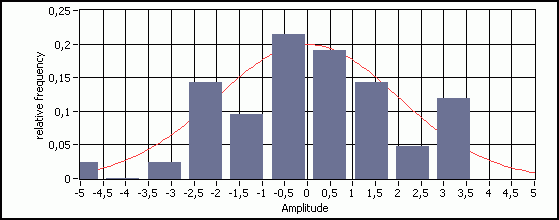
Fig. 3 : A typical relative frequency distribution of the measurement noise and the probability density.
3. State estimate equations
Literature:
- D. Joyce's (Clark University) excellent Introduction to the Expectation for continuous random variables
- D. Joyce's Introduction to the Expectation for discrete random variables
- Just a glance at the Monte Carlo method
A rough estimate of Roger's position at t=12 can be deduced from the (bad) deterministic model x=1.5t, that underestimates Roger Rabbit's speed at sapprox=1.5m/s. The model equation is transformed into the difference equation:
![]() ,
( 3.1 )
,
( 3.1 )
where we use the symbol s
rather than sapprox. Since we have no possibility
to know
s
exactly at start, we must rely on our initial approximation and consider the error
from the true value as part of the process noise. The a priori estimate
can be produced as soon as we have computed the a posteriori
estimate of the preceding point in time. Remember that one of the qualities of the Kalman filter is the
faculty to predict the next system state. In
the case of
t=12
and ![]() ,
we get
,
we get ![]() for example.
We are aware that this a priori estimate is erroneous, but we have
no idea about the variance of the error
e-.
So, let us define:
for example.
We are aware that this a priori estimate is erroneous, but we have
no idea about the variance of the error
e-.
So, let us define:
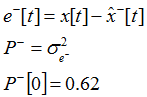
Note that we need to initialize the very first value of P- with any non-zero number, just as we did for the very first state prediction.
From the measurement we get the value ![]() with error variance
R=4.
Equation (2) may be rewritten as
with error variance
R=4.
Equation (2) may be rewritten as ![]() .
Hence it can be concluded that the state estimation, based on the
measurement alone, will exactly have the same probability density as the
measurement itself. We may fuse both estimations into the a posteriori estimation
by calculating the weighted average while using the variances as weights.
The result is a better estimate of the state,
since the conditional probability density has narrowed and
the error variance has decreased (Fig. 4) . The question whether this fusion of the
data is the best that we can do, may be answered positively. We now will
prove this. If you are not familiar with the statistical term "expectation
of a random variable E{X}", you may skip the proof or consult D.
Joyce's Introduction
to the Expectation for discrete random variables.
.
Hence it can be concluded that the state estimation, based on the
measurement alone, will exactly have the same probability density as the
measurement itself. We may fuse both estimations into the a posteriori estimation
by calculating the weighted average while using the variances as weights.
The result is a better estimate of the state,
since the conditional probability density has narrowed and
the error variance has decreased (Fig. 4) . The question whether this fusion of the
data is the best that we can do, may be answered positively. We now will
prove this. If you are not familiar with the statistical term "expectation
of a random variable E{X}", you may skip the proof or consult D.
Joyce's Introduction
to the Expectation for discrete random variables.
First
let's express the a posteriori state estimation as the weighted average of the
prediction and the measurement. In the following, for the better
readability, we will omit the time references, because the values now all
concern the point of time t.
We also will abandon the notation ![]() from the preceding document about Roger
Rabbit's path. Instead we are using the simple
from the preceding document about Roger
Rabbit's path. Instead we are using the simple ![]() .
In the general form we may write:
.
In the general form we may write:
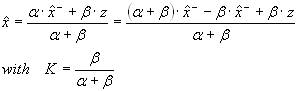
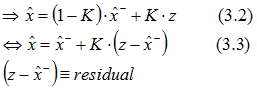
Now we will transform the variance of the a posteriori state estimation error e as a function of the variances of the prediction error and the measurement variance. It is important to take into consideration that the probability for the exact state to be situated within a certain range from the a priori predicted state is the same as the probability for the predicted state to be located within the same bounds from the exact state. In other words, there is an equivalence of considering the predicted state as the center of the probability density distribution under the condition of Roger's exact position with considering the true location as the center of the probability density distribution under the condition of the prediction. (The same is true for the measurement.) Note that we don't know the variance P- yet, but we prefixed it arbitrarily to 0.62. We can affirm that the expectation of both the measurement and the prediction is the true state x[t]. Although this proposition is easily proved by statistics, we intuitively know it from experience. In physics, if we repeat measurement experiments several times about the same state, the mean of the measurements approaches the true value. That the mean of the prediction can approach the true state is less evident. But, we know from Monte-Carlo methods that this also perfectly works. Random is a curious product, isn't it?
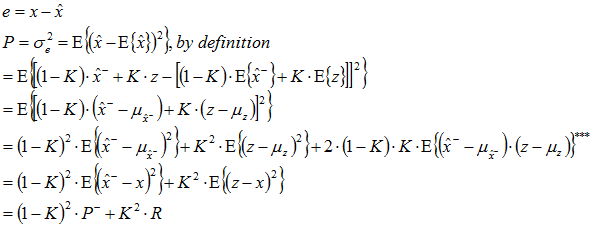
with
![]()
*** Note that this term is zero, because the prediction and the measurement are supposed to be statistically independent and therefore:
![]()
In order to minimize P, we solve the equation:
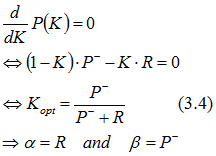
The value K is called the Kalman gain. Thus we can calculate the a posteriori estimate, assuming for this example that the a priori prediction error variance didn't change since t=0 and P-[12]=0.62:
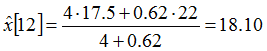
This demonstration proves that the weights R and P- are optimal in that sense that they cannot be improved. The optimal Kalman gain also minimizes the estimation error variance. (In the following we will omit the suffix "opt", because the optimal character of the Kalman gain is explicit.)
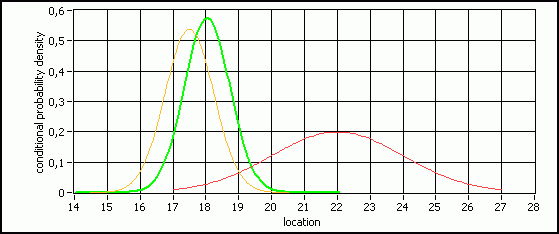
Fig. 4 : Conditional probability density at t=12 based on the model prediction and the measurement. The green curve has better variance and is closer to the true state than the others.
4. Estimation error equations
Literature:
- Excellent site about the general scalar Kalman filter
There still is one issue that not has been solved so far, although we were able to improve the state estimate by merging the model prediction with the measurement. The whole calculation has been founded on an estimation of the a priori process variance that has been prefixed arbitrarily. Because we don't know the state exactly, we have no direct possibility to deduce the degree of confidence of the a priori state estimate. In other words, since we cannot calculate the error between the true and the predicted state - and this value is essential in the equations above - we can not know, if our estimate is valuable or not. It is therefore essential to find a clear expression for the a priori process noise.
We now need to reintroduce the time reference, because values from the preceding time point appear in the equations:
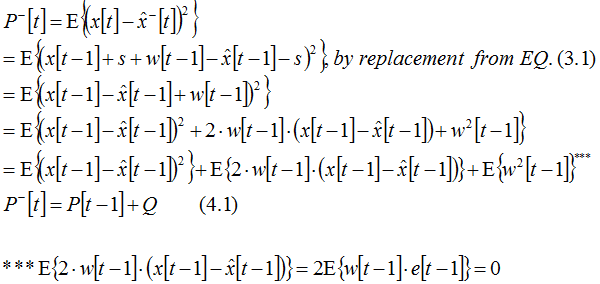
Note that the last term is zero, because the measurement and the process noise are assumed to be uncorrelated.
If we rearrange (EQ. 3.4), then we can express R as a function of K and P- and rewrite the prediction noise equation with time reference omitted:
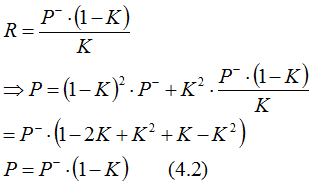
5. Convergence of the estimation noise sequence
Literature:
The reader will certainly have noticed that EQ. (4.1) and (4.2) form a recursive system of equations. The first step predicts the a priori prediction noise variance from the preceding a posteriori variance, while the second step defines the actual a priori variance on the base of the actual a posteriori variance. We know from EQ. (3.4) that the Kalman gain directly depends on the a priori prediction variance, so we merge the three equations. Again we need the time reference here: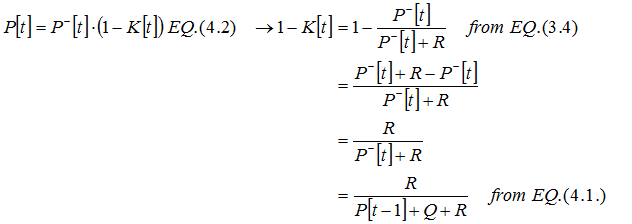
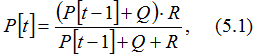
This equation represents a recursive
sequence. In order to prove that this sequence converges to a finite
limit, we must prove two things: first
that the sequence is monotonous and second that it is bounded. Let's
suppose for a moment that the sequence converges to a finite limit. This
means that if t tends to ![]() ,
P[t]-P[t-1]=0.
The limit can be calculated as follows:
,
P[t]-P[t-1]=0.
The limit can be calculated as follows:
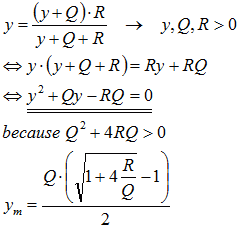
Note that we only need to retain the positive root. If we define the function:
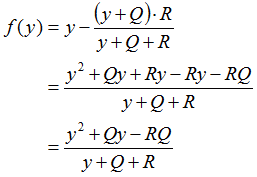 ,
,
and we set P[t-1]=y, we observe that the sign of the numerator of f(y) serves as an indicator of the type of sequence. For instance, it proves that P[t]<P[t-1] in the case of y>ym and P[t]>P[t-1] for y<ym, and the sequence is monotonously increasing for any P[0]<ym and monotonously decreasing for any P[0]>ym. The trivial case, where P[0]=ym results in a constant sequence.
In order to prove that the sequence is bounded, we consider the function:
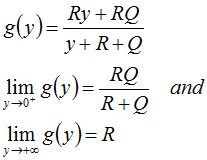
We have for all R,Q >0:
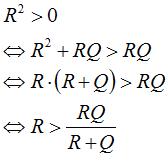
and the function g(y)
is bounded in the interval ![]()
The consequence is that, in the case of invariable R and Q, the estimation error variance can be calculated at system start. The estimation noise variance reaches an optimum that cannot be improved. An important quality of the Kalman filter is that the noise variance sequence converges rather quickly. (Fig. 5 & 6) show the convergence of the process variance in the case of Roger Rabbit's first Kalman filtering. The error variance stays within the bounds:
![]()
and the limit is
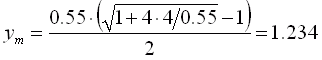 .
.
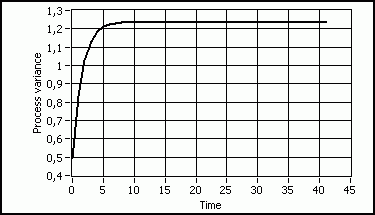
Fig. 5 : Evolution of the error variance in the case of Q=0.55 and R=4 and P-[0]=0.01
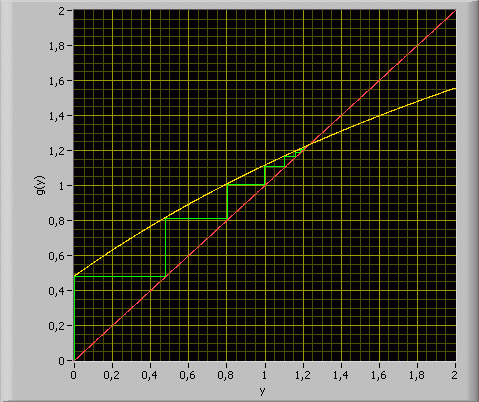
Fig. 6 : The yellow curve represents the function g(y) -see text-. The green segments develop the sequence of the error variance.
6. The Kalman filter algorithm
Literature:
- G. WELCH and G. BISHOP's excellent site about the Kalman filter
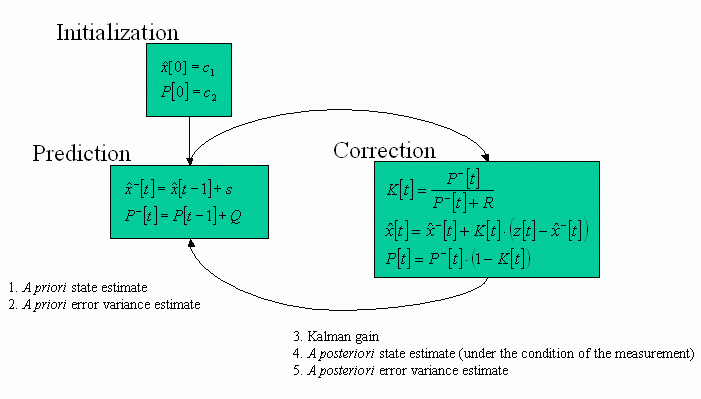
NOTES: The Roger Rabbit experiments demonstrate well that R and Q must not necessarily be constant throughout the process. If they change in time, so does the process noise and the variance starts varying accordingly. This does not affect the Kalman filter's minimizing and optimizing capabilities. If more measurement sources are present in the system, they are fused with a weighted averaging function that is very similar to the one developed in section 3 of this document (and that is well described in the Maybeck article.)